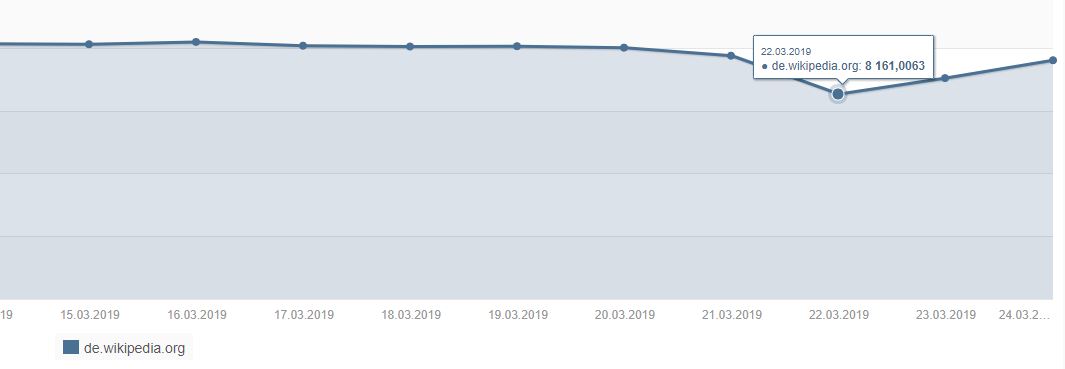
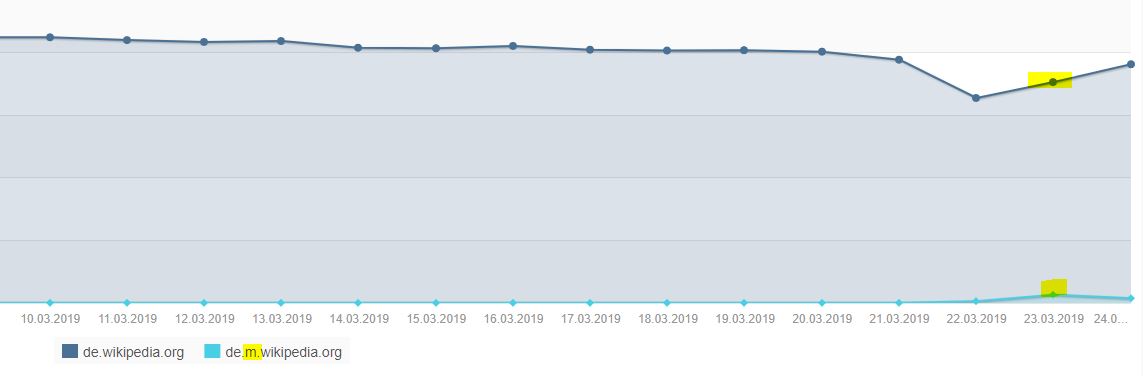
Einer der größeren Verlierer (Top 6 von 100) des letzten Google Updates ist lt. Searchmetrics die Frage & Antwort-Plattform gutefrage.net. Dieser Absturz muss überraschend gekommen sein, nach dem Head of SEO von gutefrage, Melanie Ruf, erst wenige Wochen zuvor im Oktober 2018 mit Stolz eine Steigerung von 150% Visibility verkündete. Ziel war es mit der Unterstützung des Searchmetrics Consulting Teams die SEO Abwärtsspirale bei gutefrage.net aufzuhalten. Nach dem Medic-Update im August 2018 sah alles danach aus, dass diese SEO Strategie aufgehen sollte – die Seite legt lt. Sistrix um 89% zu und galt damit als Top-Gewinner bei diesem Update. Der nun erfolgte Einbruch revidiert diese SEO Strategie deutlich und lässt die Plattform auf einen historischen Tiefststand fallen.
Q&A Sites haben es aktuell nicht leicht in den Google Ergebnissen, auch quora.com verlor leicht Punkten in den USA. Das Q&A Format basierend auf vom Nutzer eingereichte Fragen verliert zunehmend an Bedeutung in den Ergebnissen. Auch der damals sehr erfolgreiche internationale Versuch von Yahoo Answers rutscht mittlerweile in die Bedeutungslosigkeit. Dieses Problem scheint ein generelles Problem im Umgang mit nutzergenerierten Inhalten innerhalb des eingesetzten Algorithmus zu sein – jeder redaktionell moderierte Inhalt gewinnt dieser Tage vor einem unmoderierten nutzergenerierten Inhaltsformat – ob Forum oder Q&A. Die Wikipedia – bildet hierbei eine extreme Ausnahme.