Google hat neue Meta-Tags eingeführt, die eine feingranulare Anzeigensteuerung der Suchergebnis-Snippets ermöglicht. Mit Hilfe der drei neuen HTML-Tags lässt sich die maximale Zeichenzahl der Text-Snippets definieren, die Dauer der Video-Vorschau und die Bildgröße der Preview-Bilder festlegen. Nähere Informationen zu den neuen Meta-Tags findet man hier.
Interessant an der ganzen Geschichte ist, wie die Einführung der neuen Meta-Tags verkauft worden ist. Google gibt sich freundlich & sozial und spricht davon, dass die Tags den Webmastern helfen und ihnen mehr Freiheit bei der Aussteuerung der Ergebnis-Snippets verleihen. Dass Google zu diesem Schritt von der EU gezwungen worden ist, wird dabei verschwiegen.
Fußen tut das Ganze auf folgendem Sachverhalt: Websites, die gemäß EU-Richtlinie 2019/790 über das Urheberrecht und die verwandten Schutzrechte im digitalen Binnenmarkt als „europäische Presseveröffentlichung“ gekennzeichnet werden, unterliegen den neuen Richtlinien. Diese Information wurde betroffenen Webmastern über die Google Search Console mitgeteilt:
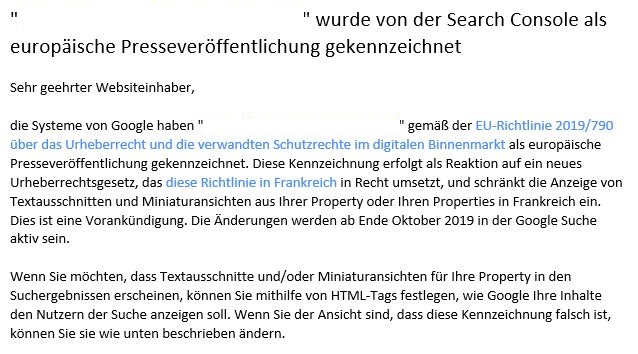
Diese Vorankündigung wird ab Ende Oktober 2019 in der Google Suche in Frankreich aktiv sein.